Data Compression Techniques
最近读了比较多的关于数据压缩的论文,具体的论文阅读记录后续会慢慢抽时间写出来,本文先对最近所读简单地进行一个归纳与总结。主要按照以下目录分几个方面来进行总结。
Motivation
现在的应用程序多为数据密集型;
内存需求近些年一直在增加;
而DRAM作为最常见的系统内存,存储密度低,简单来说就是,目前单个DRAM芯片的集成度已经接近极限,远不能满足大数据对内存容量TB级甚至PB级的需求。显然,数据压缩技术对于未来的系统是必不可少的。
Benefits of Data Compression
为什么研究数据压缩,肯定是因为有好处,有前景,那么有哪些好处呢?
不增加内存大小,就能获得更多的有效容量;
避免内存溢出:尤其适用于嵌入式系统;
减少缺失率和带宽占用;
节省能耗,在能耗相同的情况下,能够做更多的计算。
此外,在NVM和3D内存中尤其适用,能够:
减少写数据量和写能耗;
减轻NVM的耐力问题;
Storage Compression(例如,缓存压缩):减少数据存储能耗
Bandwidth Compression:减少数据移动能耗
Opportunities for Compression
就目前研究来看,什么情况下什么类型的数据经常被压缩?
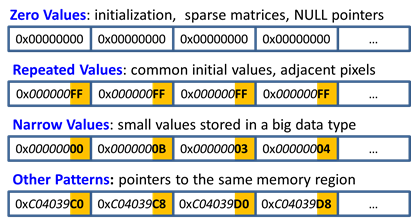
常量、数据复制和赋值
使用公共值初始化
较大的数据类型用于存储较小的数据
特殊值的大量出现,如0,1
以上情况下的数据有很大的冗余,能够考虑利用压缩来消除冗余,具体是什么类型的数据用下图程序段来举例说明。

- 图片
目前有很多利用图片中相邻像素点值差异很小这一特点来进行的相关研究。

针对以上前四种数据类型,很多论文中有专业的名词来表示它们,分别是Other Patterns、Repeated Values、Narrow Values、Zero Values。
Challenge in using Compression
任何一种技术都不可能十全十美,那么压缩有啥坏处呢?
有压缩那就对应地有解压缩,而压缩和解压缩都会产生额外的延迟和能耗,压缩延迟不在关键路径上,但是解压缩延迟位于缓存命中的关键路径上,对性能影响很大。
往往现有的压缩率高的压缩算法,对应的就会有复杂的硬件设计,同时有很高的解压延迟开销。
压缩仅在最后一级cache和main memory中有用,因为在L1 cache中存储压缩数据,由于解压缩带来的延迟开销无法接受。
由于压缩是变长的,使得不同cache line的压缩不能并行。
有些技术单独存储未压缩的line,由于复杂的硬件设计会造成很重的开销。
存在某些不可压缩的数据(如加密数据)或低效的压缩算法。
压缩块大小不是固定的,这会使得后续寻址变得困难,因为压缩前原有的线性映射会发生变化,或者由于压缩产生碎片可用空间。
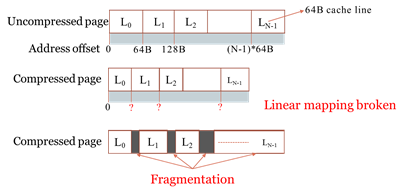
删除和插入数据的大小可能不同,导致替换策略变得复杂。
最重要的一个问题,会或多或少产生额外的元数据,带来额外的存储开销。
如果应用程序内存占用已经很小,压缩没有多大用处,如果内存占用较大,则压缩提供的额外容量也不够,这样来看怎么压缩好像显得有点鸡肋?
Need of Carefully Choosing Data-Block Size
如何选择压缩数据块的大小,即压缩粒度怎么决定?越大越好or越小越好?
大的数据块大小作为压缩粒度:大块内会有更高的冗余,似乎还能够获得更高的压缩比,而且元数据存储开销也会比较低。但是即使只访问大块(例如,2KB)之中的某一个子块(例如,64B),也需要解压整个大块,产生无谓的解压开销,而这很影响性能。此外,在大块内想要找到特殊的模式(例如全为零)比较困难。
小的数据块大小作为压缩粒度:与以上相反,此优点为彼缺点吧!值得注意的是,tag元数据存储开销会大大增加。
因此可以看出,压缩粒度的选择需要根据不同类型应用程序动态选择。
Some Compression Algorithm
Huffman coding
Lempel-Ziv (LZ) algorithm (and derivatives)
X-match and X-RL
Frequent value compression (FVC)
Frequent pattern compression (FPC)
C-PACK
Base delta immediate (BDI) compression
Zero-value and narrow-value detection
…
Granularity of Exploiting Redundancy
Across different blocks of the whole cache (also called deduplication)
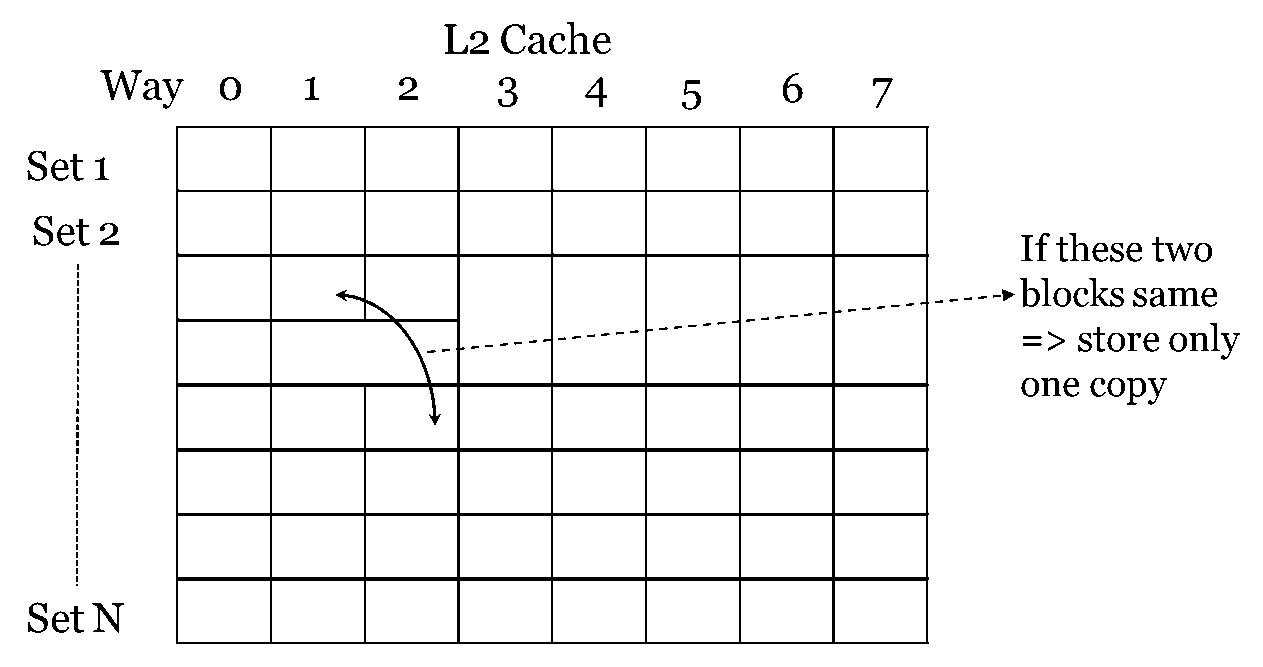
Across different words of a cache block
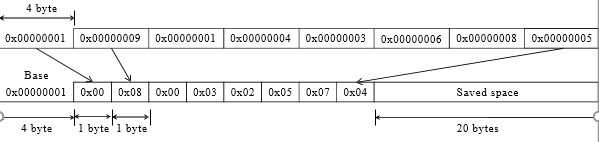
Across different bytes of a cache word
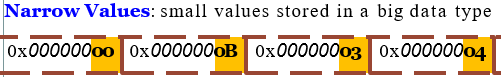
原文作者: malizhen
原文链接: http://malizhen.github.io/2019/06/26/Data Compression Techniques总结/
版权声明: 转载请注明出处(必须保留原文作者署名及原文链接)